
PF_RING™
High-speed packet capture, filtering and analysis.
PF_RING™ is a new type of network socket that dramatically improves the packet capture speed, and that’s characterized by the following properties:
- Available for Linux kernels 2.6.32 and newer.
- No need to patch the kernel: just load the kernel module.
- 100 Gbit Hardware-based Packet Filtering using commodity network adapters on Intel and NVIDIA/Mellanox.
- User-space ZC drivers for extreme packet capture/transmission speed as the NIC NPU (Network Process Unit) is pushing/getting packets to/from userland without any kernel intervention. Using ZC drivers you can send/received up to 100 Gbit wire-speed any packet size.
- PF_RING ZC library for distributing packets in zero-copy across threads, applications, Virtual Machines.
- Agnostic API for device driver independent application code.
- Zero-copy support for Intel, NVIDIA (Mellanox), Napatech, Silicom FPGA (Fiberblaze), and other network adapters.
- Kernel-based packet capture for all adapters, when not supported by ZC.
- Libpcap support for seamless integration with existing pcap-based applications.
- Optimized nBPF filters in addition to the legacy BPF.
- DPI content inspection with nDPI, so that only packets matching the desired L7 protocols are passed.
If you want to know about PF_RING™ internals or for the User’s Manual visit the Documentation section.
Vanilla PF_RING™
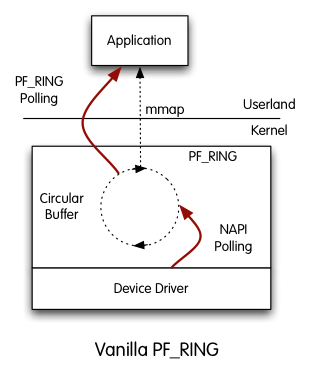
PF_RING™ is polling packets from NICs by means of Linux NAPI. This means that NAPI copies packets from the NIC to the PF_RING™ circular buffer, and then the userland application reads packets from ring. In this scenario, there are two pollers, both the application and NAPI and this results in CPU cycles used for this polling; the advantage is that PF_RING™ can distribute incoming packets to multiple rings (hence multiple applications) simultaneously.
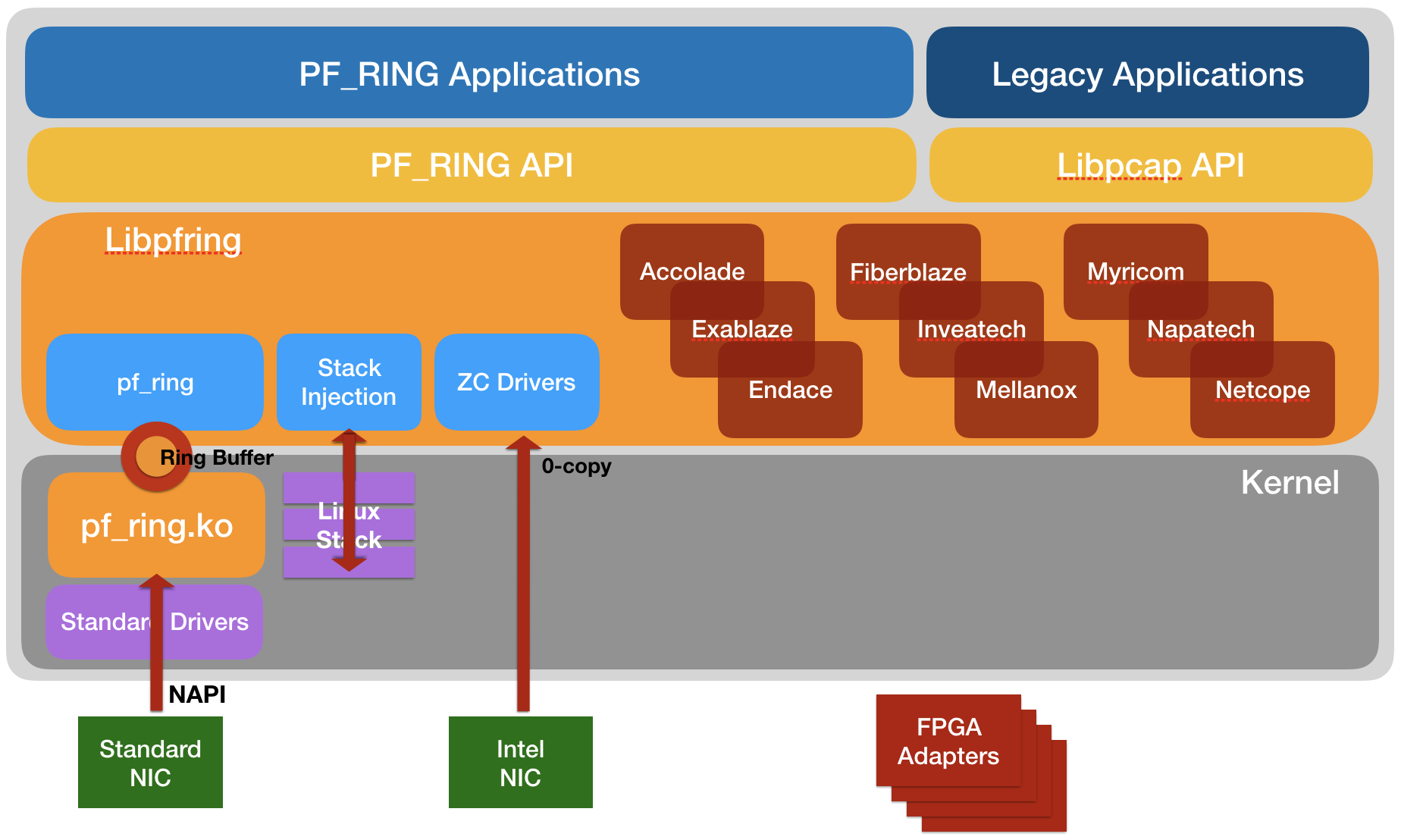
PF_RING™ Modules
PF_RING™ has a modular architecture that makes it possible to use additional components other than the standard PF_RING™ kernel module. Currently, the set of additional modules includes:
- ZC module.
This module supports zero-copy capture with Intel adapters. Have a look at the ZC page for additional information. - FPGA-based card modules.
Those modules add zero-copy support for many vendors including NVIDIA (Mellanox), Napatech, Silicom FPGA (Fiberblaze) and others. - Stack module.
This module can be used to inject packets to the linux network stack. - Timeline module.
This module can be used to seamlessly extract traffic from a n2disk dump set using the PF_RING™ API. - Sysdig module.
This module captures system events using the sysdig kernel module.

{kind=link}
Who needs PF_RING™?
Basically everyone who has to handle many packets per second. The term ‘many’ changes according to the hardware you use for traffic analysis. It can range from 80k pkt/sec on a 1.2GHz ARM to 148M pkt/sec on a 3GHz Xeon Scalable. PF_RING™ not only enables you to capture packets faster, it also captures packets more efficiently preserving CPU cycles. Just to give you some figures you can see how fast nProbe, a NetFlow v5/v9/IPFIX probe, can go using PF_RING™, or have a look at the tables below.
10 Gigabit tests performed on a low-end Xeon 2.5 Ghz:
| ixgbe | |||
|---|---|---|---|
| Application | Driver | Rate | |
| pfcount (RX) | PF_RING™ ZC | 14.8 Mpps | |
| pfsend (TX) | PF_RING™ ZC | 14.8 Mpps | |
1 Gigabit tests performed using a Core2Duo 1.86 GHz, Ubuntu Server 9.10 (kernel 2.6.31-14), and an IXIA 400 traffic generator injecting traffic at wire rate (64 byte packets, 1.48 Mpps):
| igb | |||
|---|---|---|---|
| Application | Driver | Rate | |
| pcount – vanilla libpcap | Standard | 544 Kpps | |
| pcount – PF_RING™-aware libpcap | Standard | 613 Kpps | |
| pfcount | Standard | 650 Kpps | |
| pfcount | PF_RING™ ZC | 1’488 Kpps | |
NOTE
- pfcount is an application written on top of PF_RING™, whereas pcount as been written on top of libcap-over-PF_RING™. As applications are just counting packets with no extra processing, pfcount (with -a that means active packet polling) is sometimes slower of pcount that has to pay the libpcap overhead. This is justified by the fact that pfcount processes packets faster than pcount, hence it consumes all packets available quicker hence it calls the poll() (i.e. wait for incoming packets) more often. As poll() is rather costly, pcount performance is better than pfcount on this special case. In general applications have to do something with packets beside counting them, hence the performance of pure PF_RING™-based applications should be better than pcap-based applications.
- For wire-rate packet capture even on a low-end Core2Duo PF_RING™ ZC is the solution.
Operating Systems
![]()
Documentation
License
PF_RING™ kernel module and drivers are distributed under the GNU GPL license, LGPL for the user-space PF_RING library, and available in source code format.
Get it
| Product | Availability |
|---|---|
| PF_RING™ | |
| PF_RING™ ZC 1/10/40/100 Gbit | Visit the PF_RING ZC section. |
* This work is the result of the last couple of years of self-funded research. We therefore ask you a little help to keep the project running. Nevertheless if you’re a no-profit organization, professor or university researcher, please drop us an email and we’ll send it to you for free.